Avec les avancées récentes dans les domaines des modèles de langages massifs (LLM) et du NLP (Natural Language Processing), les approches de QA (Question Answering) ont très largement gagné en popularité. Nous allons dans cet article essayer de comprendre :
- En quoi consiste ce type d’approche
- Comment ça fonctionne ?
- Les limitations associées à ce type d’approche
Présentation des systèmes de QA
Les systèmes de QA ont pour but de répondre automatiquement à des questions formulées en langage naturel à partir d’une base de documents. Contrairement aux moteurs de recherche dont le résultat est un ensemble de documents (laissant ainsi le mining d’informations à la charge de l’utilisateur), les applications de QA fournissent directement une réponse à la question en utilisant le contenu des documents. La forme de cette réponse peut varier selon le type d’architecture choisie, dans les architectures les plus simples la réponse est souvent un extrait d’un des documents.

Ce type d’approche peut être particulièrement intéressant pour plusieurs raisons :
- Gain de temps dans le contexte d’une base de document très étendue et/ou difficilement navigable manuellement.
- Interaction de manière plus ‘naturelle’ avec les documents.
- Plus de flexibilité qu’un moteur de recherche sur la forme des requêtes et des documents.
Les systèmes de QA existaient avant les avancées récentes en NLP et utilisaient des techniques complexes et variées d’Information Retrieval. Au sein d’un système de QA un modèle de langage pourra aider afin de :
- Comprendre la question posée
- Générer une réponse cohérente à partir de bouts de documents pertinents
- Lever certaines ambiguïtés du langage naturel qui ne peuvent pas être traitées correctement par des approches purement lexicales
Enfin les modèles de langages rendent ce genre de systèmes plus simples à concevoir.
Architecture d’une approche QA
Les architectures pour ce type d’approches sont très variées et il existe de nombreux frameworks associés (Haystack, Langchain, Hugging Face Transformers…). Nous présenterons ici des architectures inspirées par le framework Haystack car il présente un bon niveau d’abstraction. Les architectures que l’on va présenter ici sont des architectures simples, variées et répondant chacune à un besoin différent.
QA extractive simple
Les 3 composants principaux d’une QA extractive sont :
- Retriever : un algorithme qui permet de retourner les documents les plus pertinents pour une requête. Un Retriever est en fait un moteur de recherche léger. On utilise souvent des représentations type tfidf (représentation vectorielle du document illustrant l’importance de chaque terme du document par rapport au corpus) pour cette brique.
- Reader : un algorithme qui scan du texte et qui renvoie le bout de texte le plus pertinent pour une requête. On utilisera souvent des modèles de langage spécialisés pour cette brique.
- DocumentStore : un stock pour les documents. Ce stock est classiquement une base de données vecteur (ElasticSearch, Pinecone, Chroma, FAISS…) ou un simple stockage fichier.
La mécanique est la suivante :
- Tout d’abord on utilise le Retriever pour indexer les documents dans le DocumentStore.
- Ensuite l’utilisateur rentre une requête dans le système.
- Le Retriever retourne le top k des documents correspondant à la requête.
- Le Reader scan le texte des top k documents retournés pas le Retriever pour trouver la réponse à la question
- Le système renvoie la réponse donnée par le Reader.

En résumé, on utilise un moteur de recherche léger et lexical pour filtrer la base de documents uniquement sur des documents pertinents puis on utilise un modèle lourd et sémantique sur le contenu de ces documents pour en extraire la réponse la plus satisfaisante possible. La puissance de ce pipeline réside principalement dans le Reader qui permet de faire ce qu’un moteur de recherche classique ne pourrait pas faire.
RAG (Retrieval Augmented Generation)
Les LLM sont très efficaces quand il s’agit de fournir une interface conversationnelle à l’utilisateur.
Mais une de leurs limites importantes est leur incapacité à garantir la véracité et la provenance des informations renvoyées. A l’opposé, la QA extractive simple garantie au moins la provenance des informations renvoyées (et donc leur véracité si la réponse à la question est bien contenue dans la base de document), cependant ce genre de système ne fournit pas une interface très naturelle. Le RAG consiste alors à prendre le meilleur des deux mondes en utilisant un LLM à la fois comme Reader et comme formateur de réponse.
Dans sa forme la plus basique ce type d’approche est en fait juste la combinaison d’un moteur de recherche lexical et d’un LLM.

Multihop QA
Le multihop QA est un type d’architecture de QA qui permet de répondre à des questions pour lesquelles il faut agréger plusieurs réponses correspondant à des informations présentes à divers endroits du corpus de documents.
Imaginons que nous soyons en train de construire un programme de QA dans le contexte d’un cours d’histoire. Le corpus de documents sera par exemple l’ensemble des pages Wikipédia relatives à la seconde guerre mondiale (ainsi que toutes les pages linkées dans ces pages). On souhaite pouvoir poser des questions complexes au programme comme par exemple : ‘Quels sont les facteurs sociaux qui ont poussé au déclenchement de la seconde guerre mondiale ?’. Un programme en single hop ne pourra pas donner une réponse très évoluée à cette question, mais un programme en multihop pourra faire de nombreuses requêtes différentes pour rassembler un ensemble d’informations qu’il pourra agréger dans une seule réponse finale pour répondre à cette question.
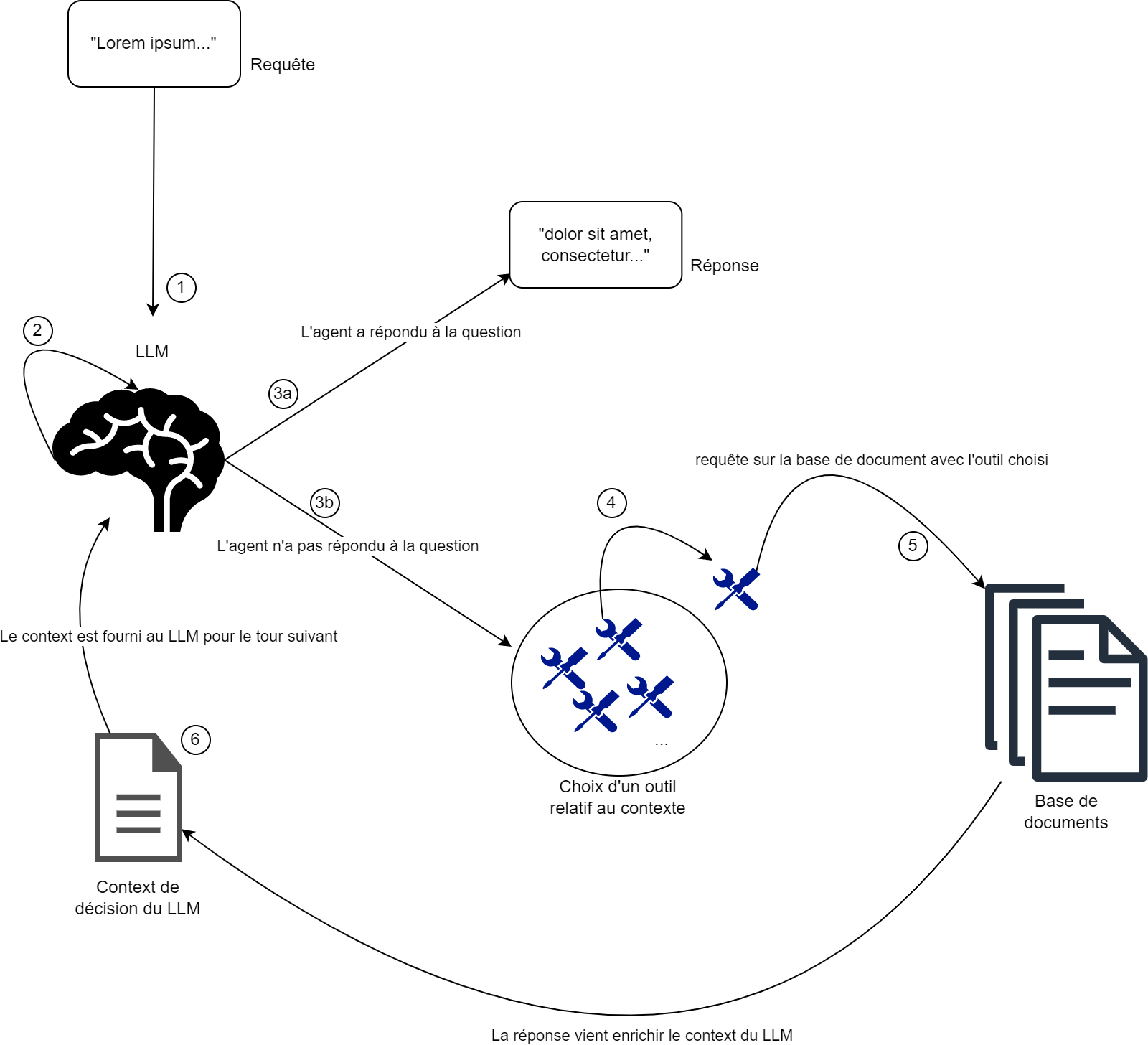
Le schéma ci-dessous explique le mécanisme sous-jacent au multihop question answering tel que proposé par le framework Haystack:

Tout d’abord dans ce genre d’architecture on a un agent qui est le cerveau du programme (ici c’est un LLM). Le multihop fonctionne par itération :
- 2) Le LLM scan son contexte et évalue s’il peut répondre à la query avec ce contexte
- 3a) Si oui il renvoie la réponse et le programme s’arrête
- 3b) et 4) Si non, il regarde les outils qu’il a à sa disposition (un outil est une pipeline de retrieval) et il choisit le plus pertinent pour son contexte et sa query
- 5) Il utilise ensuite cet outil pour requêter la base de documents
- 6) Enfin la réponse à cette requête est réinjectée dans le contexte de l’agent
- On recommence jusqu’à ce que l’agent décide qu’il peut répondre à la question
Limites, nouveautés et futur
Limites
Les approches de QA utilisant des LLM sont très prometteuses mais présentent néanmoins certaines limites :
- Le Retriever présente un sérieux bottleneck ; la scalabalité de ce Retriever devient un enjeu de performance très important lorsque la quantité d’information de la base de document augmente. De plus la qualité du Retrieve influence de manière importante la qualité des réponses du système.
- Même avec les meilleurs LLM, l’ambiguïté des questions données en entrée au système peut dégrader fortement la qualité des réponses.
- Les systèmes de QA complexes comme ceux qui font du multihop restent complexes à rendre fiables, en particulier quand les questions posées présentent des subtilités et/ou demandent du raisonnement.
- La qualité d’un système de QA est limitée mécaniquement par la qualité des informations contenues dans sa base de documents.
Perspectives
Dans cet article nous avons concentré notre attention sur les systèmes de QA textuels. Néanmoins les avancées récentes en machine learning ont rendu possible la construction de systèmes de QA multimodaux pouvant générer des réponses à partir de types de médias variés : vidéos, audio et images. Ce genre d’approche est rendu possible notamment par la possibilité de vectoriser ces médias dans des espaces latents sous une forme plus facilement manipulable et présentant des caractéristiques intéressantes. Un bon exemple de ce genre d’embedding est l’algorithme CLIP de OpenAI qui permet de vectoriser du texte et des images dans un espace où il est possible de les comparer et donc de calculer une forme de similarité transmédia.
Certains des enjeux et des perspectives concernant les approches de QA sont par exemple :
- L’évaluation de ces systèmes. De même que pour les LLMs il existe de nombreux frameworks permettant d’évaluer ce type de systèmes mais c’est un sujet complexe qui est encore en actuellement en développement.
- Ajuster l’équilibre entre recherche lexicale (Retrieval) et recherche sémantique (Reader) car les LLM ont des contextes de plus en plus grands et des performances de plus en plus élevées. On peut alors se permettre de pencher vers des systèmes qui font un retrieval plus étendu afin de profiter de la puissance des LLM pour générer la réponse.
- Concevoir des systèmes de QA plus sensibles au jargon de certains domaines afin de les rendre plus pertinents.