Après avoir posé ce que pouvait être une démarche référentielle et souligné les écueils d’une telle démarche, il s’agit maintenant d’identifier quelques principes d’urbanismes applicables aux données de référence.
Ces principes sont à utiliser comme des indications et non comme des lois ou des dogmes. Il est tout à fait possible que par moment, violer ou s’écarter de ces principes soit une bonne option. Néanmoins, il convient de bien vérifier les motivations de ces écarts, la plupart étant de fausses bonnes idées.
Il ne s’agit que des principes de base de gestion des données de références, il convient de les enrichir et les adapter avec :
• le retour d’expérience suite à la mise en œuvre des premiers référentiels dans le SI,
• des illustrations et des exemples concrets appliqués dans les projets pour communiquer plus efficacement auprès des autres projets,
• une adaptation au contexte de chaque système d’information.
Unicité du référant
L’objectif de l’unicité du référant est de favoriser la cohérence des données référentielles au sein du SI.
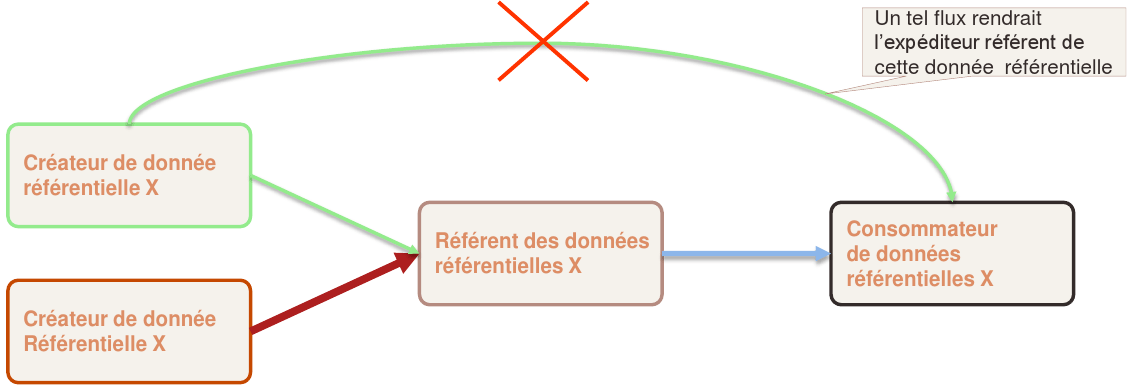
Ce principe propose que pour chaque type de donnée référentielle il y ait unicité du référant. Par exemple, un seul référentiel produit, un seul référentiel fournisseur. Plusieurs points importants sont à préciser :
• Le référant n’est pas nécessairement le créateur de la donnée référentielle.
• Il n’y a pas de contrainte d’unicité des sources de données référentielles sur des périmètres disjoints. Par exemple le référentiel des personnes peut provenir de deux systèmes de Paye qui concernent chacun des populations différentes de l’entreprise.
• Dans le cas d’applications très intégrées entres-elles, l’une d’elles peut jouer le rôle de point de diffusion pour les autres – elles sont vus comme globalement une seule application dans le circuit de diffusion des données référentielles.
Centralisation des mises à jour
Bien que leur cycle de vie soit souvent plus lent que les données opérationnelles, les données référentielles ne sont pas immuables. Elles font l’objet de mises à jour et ce n’est pas toujours le référant ou même le créateur de la donnée qui est à l’initiative de cette mise à jour. Il s’agit souvent de contribution sur des facettes particulières des données référentielles.
Le référant doit toutefois être le point de centralisation et diffusion de ces mises à jour pour favoriser la cohérence des données référentielles et éviter à chaque consommateur d’être à l’écoute des contributions de chacun.
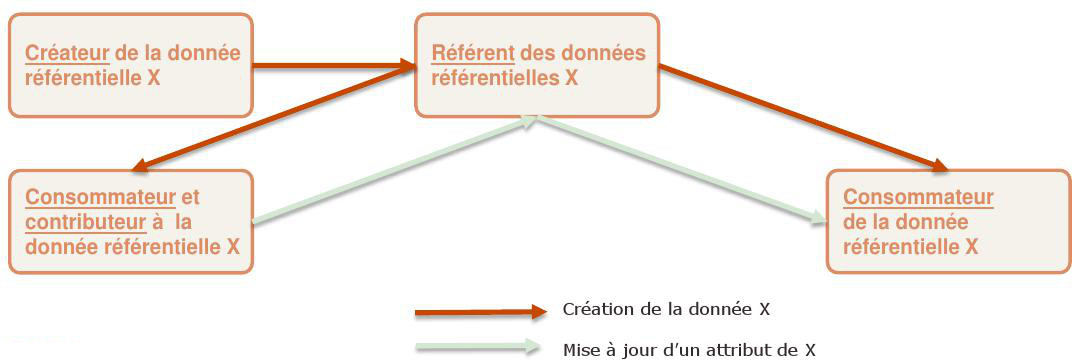
Les modifications d’une donnée sous contrôle d’un référentiel sont diffusées par le référentiel uniquement si cette modification est susceptible d’être utilisée par d’autres applications.
Une exception particulière à cette règle concerne les ensembles d’applications très intégrées entre elles (plusieurs applications d’une suite progicielle exemple) ou l’une joue un rôle de mandataire pour les autres.
Unicité de l’identifiant
L’unicité de l’identifiant a pour objectif de faciliter les possibilités de rapprochement des données référentielles et les correspondances entre les applications.
Une donnée référentielle possède un unique identifiant fourni par le référant. Cet identifiant est la clé qui permet à tout composant du SI (producteur ou consommateur) de pouvoir identifier et distinguer les données référentielles. Ceci n’empêche pas une donnée référentielle d’avoir une codification propre dans chaque composant du SI qui l’utilise. C’est souvent le cas dans un progiciel qui gère ses propres codifications internes mais aussi dans toute application qui a le bon gout de gérer dans son modèle de données les liens avec des clé technique et non les clé fonctionnelles.
Le référentiel est également en charge des gérer les identifiants alternatifs et la correspondance avec l’identifiant standard. Cela permet de gérer les identifiants « historiques » des applications ; le référentiel étant rarement la première brique construite dans le SI ! Ceci est par ailleurs une nécessité pour les applications (en général progiciel) qui ne permettent pas d’utiliser un identifiant externe. L’idée est que le référentiel fournisse à chacun la table de correspondance afin que ces identifiants spécifiques ne contaminent pas tout le SI et soient éliminés dans les couches d’interfaces au plus tôt.
Indépendance du référant
L’indépendance du référant est sans doute le principe le plus délicat à mettre en œuvre. L’objectif est d’amortir le plus possible les impacts sur le SI de l’évolution des applications qui créent les données référentielles. Le référant faisant écran des évolutions et transitions entre les créateurs/contributeurs des données référentielles et les consommateurs.
Pour assurer cette indépendance, la structure de la donnée dans le référant doit être la plus indépendante possible des producteurs et des consommateurs :
• Indépendance de la structure technique : format, type, nommage
• Indépendance de la structure fonctionnelle : règles de gestion spécifiques et modèle conceptuel des données
Cette indépendance est toujours relative et les formats sont souvent teintés des applications créatrices de données référentielles. Les formats pivots purs et parfaitement indépendants n’existent que dans les livres et les organismes de normalisation ou dans de rares cas simples de données largement échangées. Il s’agit donc de trouver le compromis entre les gains à s’aligner en partie sur le format et les concepts de l’application créatrice et la capacité à gérer le remplacement de cette application sans impact trop lourd sur les consommateurs.
Dans le cas ou le référentiel est porté par une application métier de type progiciel, il faut bien prendre en compte les limites suivantes :
• Les consommateurs de ces données référentielles seront contraints par la modélisation et l’évolution propres au métier de cette application. Les capacités d’adaptation (au-delà de simples attributs personnalisés) du progiciel sont donc à étudier de près avant de prendre une telle décision.
• Ce référentiel ne peut être qu’un sous-ensemble des données gérées par cette application. Si ces données sont étendues et que le progiciel n’en gère qu’une partie, les deux options ne sont pas idéales : charger dans le progiciel des informations qu’il ne gère pas, au risque de l’alourdir, pour maintenir son rôle de référentiel, ou bien créer un second référentiel pour ce nouveau périmètre de données.
Ce raccourci, qui consiste à s’appuyer sur un progiciel métier comme référentiel, est souvent une bonne option pour les SI de petite taille ou bien complètement structuré autour d’un progiciel intégré qui couvre la majorité des métiers de l’entreprise. Cela est toujours plus simple à mettre en œuvre et le couplage aux formats des données référentiels n’a que peu de conséquences pour les SI déjà entièrement modelé autour d’un progiciel.
Mise sous contrôle d’une donnée référentielle
La mise sous contrôle d’une donnée référentielle a un cout et toutes les données référentielles ne nécessitent pas autant d’attention.
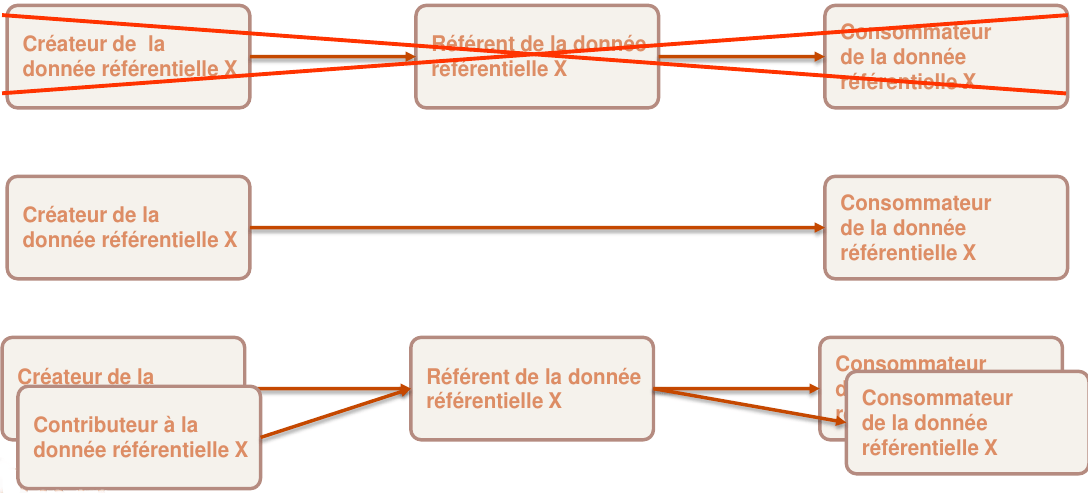
En première approche, il est souhaitable de mettre une donnée référentielle sous le contrôle d’un référentiel quand au moins une de ces conditions est remplie :
• Quand elle est produite par plus d’une application
• Quand elle est consommée par plus d’une application
• Quand les fonctions à valeurs ajoutées du référentiel (historisation, gestion à date etc.) sont souhaitées
Conclusion
Ces principes ne sont qu’une ébauche qu’il convient d’adapter à chaque contexte (taille du SI, présence ou non d’un ERP jouant un rôle de centre de gravité…) et à chaque donnée référentielle (niveau de diffusion, multiplicité et stabilité des sources etc,). Le référant, point de vérité de la donnée référentielle, se doit de posséder plusieurs qualités et fonctionnalités pour justifier son existence. Celles-ci seront développées dans le prochain article de cette série.